
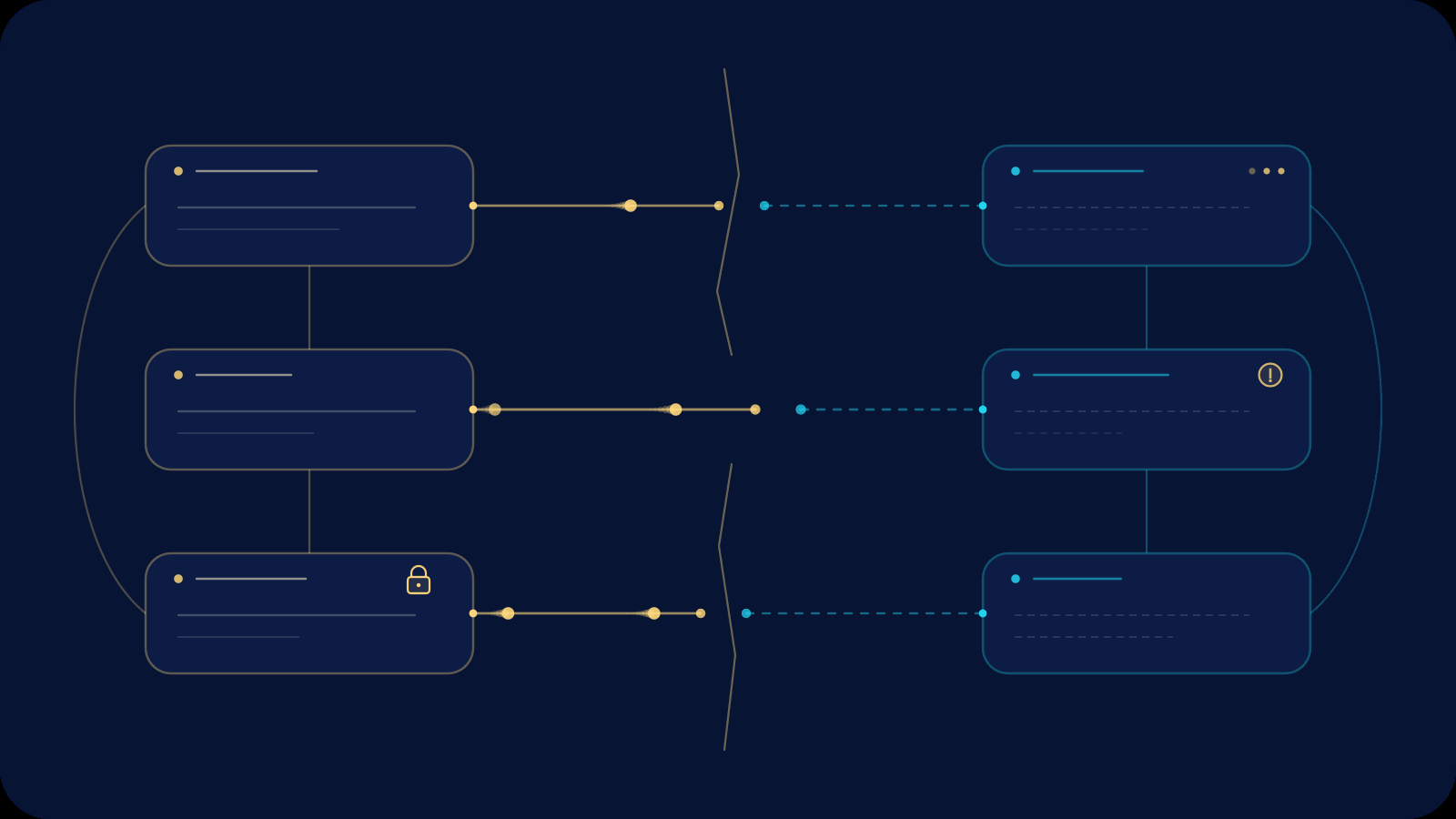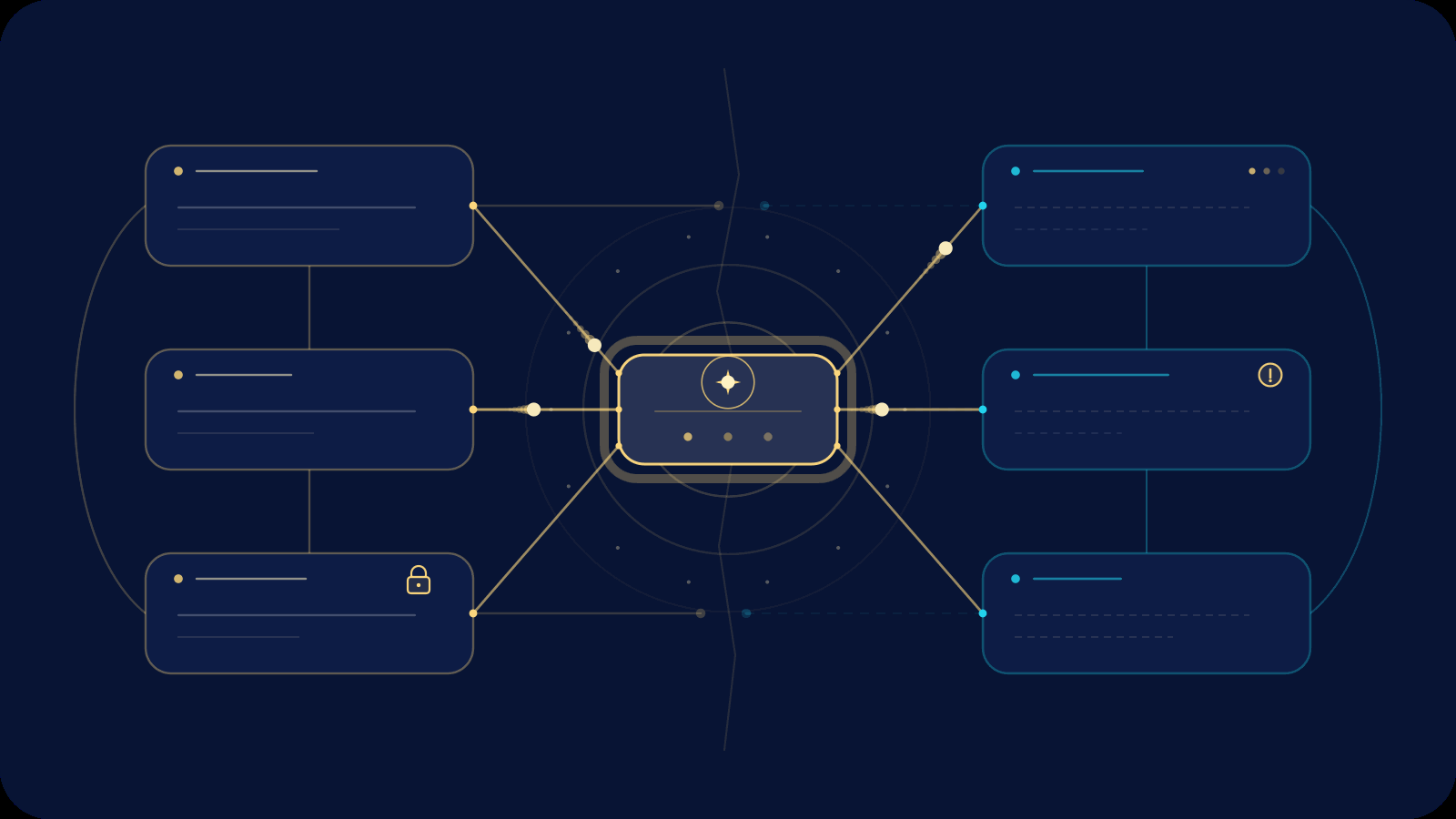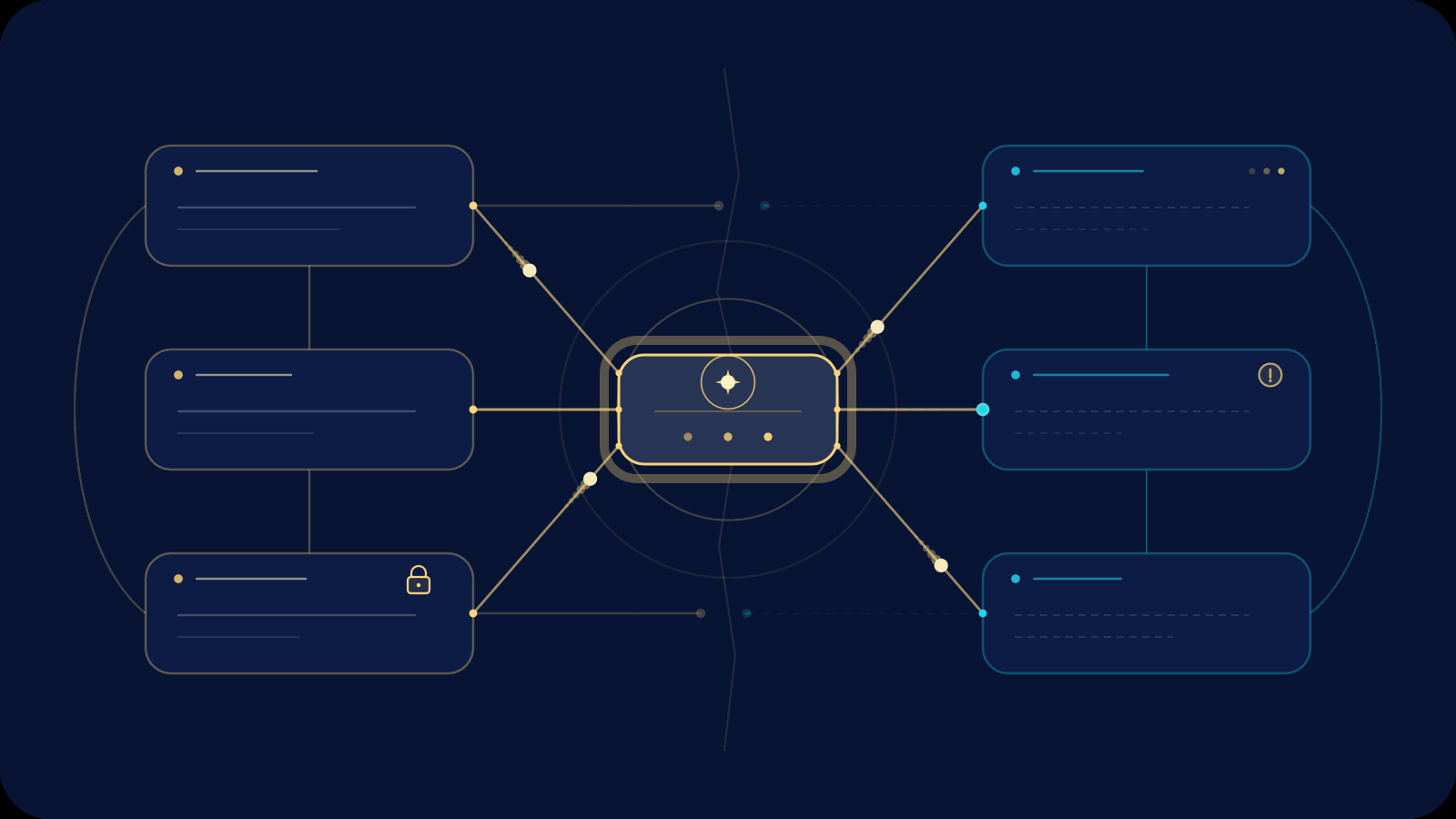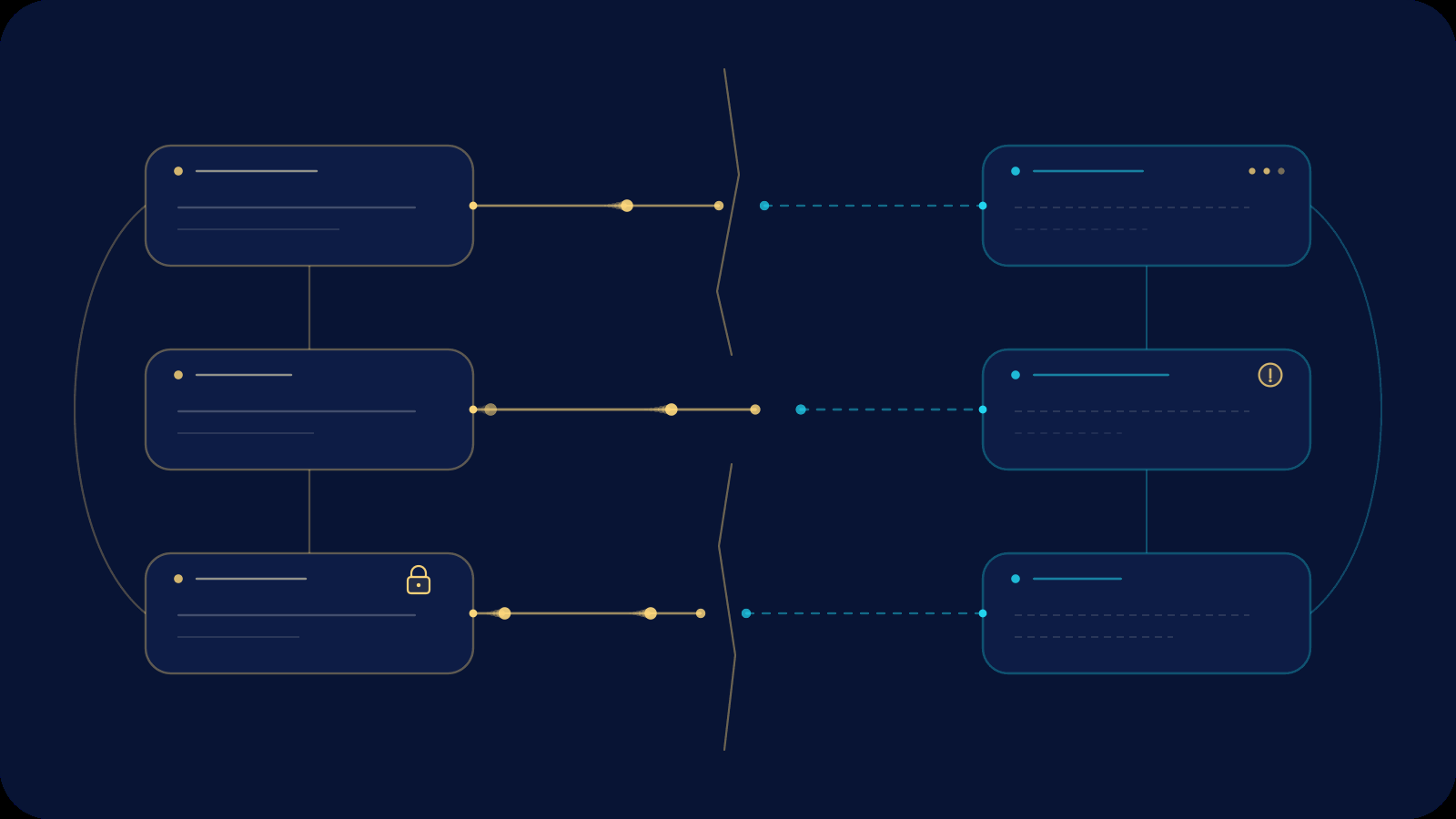
The Data Mesh promised a revolution: domain teams owning their own analytical data as high-quality, self-serve products. No more central bottlenecks. No more months-long waits for the right dataset. Just autonomous domains delivering trustworthy data that consumers could actually use.
Yet in practice, many organizations watch their mesh fracture—not because the technology fails, but because the surrounding organizational structure and politics quietly erode its utility. Processes emerge that look like “governance” on paper but function as guardrails limiting what data consumers can discover, interpret, or act upon. The result is a decentralized architecture that, in reality, recentralizes control in subtler ways.
This isn’t accidental. It’s the predictable outcome of misaligned incentives and communication structures. In this post we’ll examine why Data Mesh was created, how organizational theory explains its common fractures, the specific mechanisms that limit consumer power, and—most importantly—how agentic data engineering can realign roles so the mesh finally delivers on its promise.
Why Data Mesh Was Introduced in the First Place
By the late 2010s, enterprises were drowning in data lakes and warehouses. Central analytics teams had become bottlenecks: every new consumer request required pipeline changes, schema approvals, and months of engineering time. Data quality suffered. Delivery slowed. Domains closest to the source data had the deepest knowledge but no ownership or incentive to maintain analytical products.