AI agents are great at building data pipelines that look like they work until you dig into the results.
Write-audit-publish (WAP) helps fix that. Stage the data, audit it against a declared contract, and only publish once every clause passes. Netflix popularized this pattern in 2017.
A pipeline that finishes successfully is not the same as one whose output is correct.
We’ve built a number of internal skills to make our own data pipelines safer, and this one felt useful enough to release as a free WAP skill for coding agents.
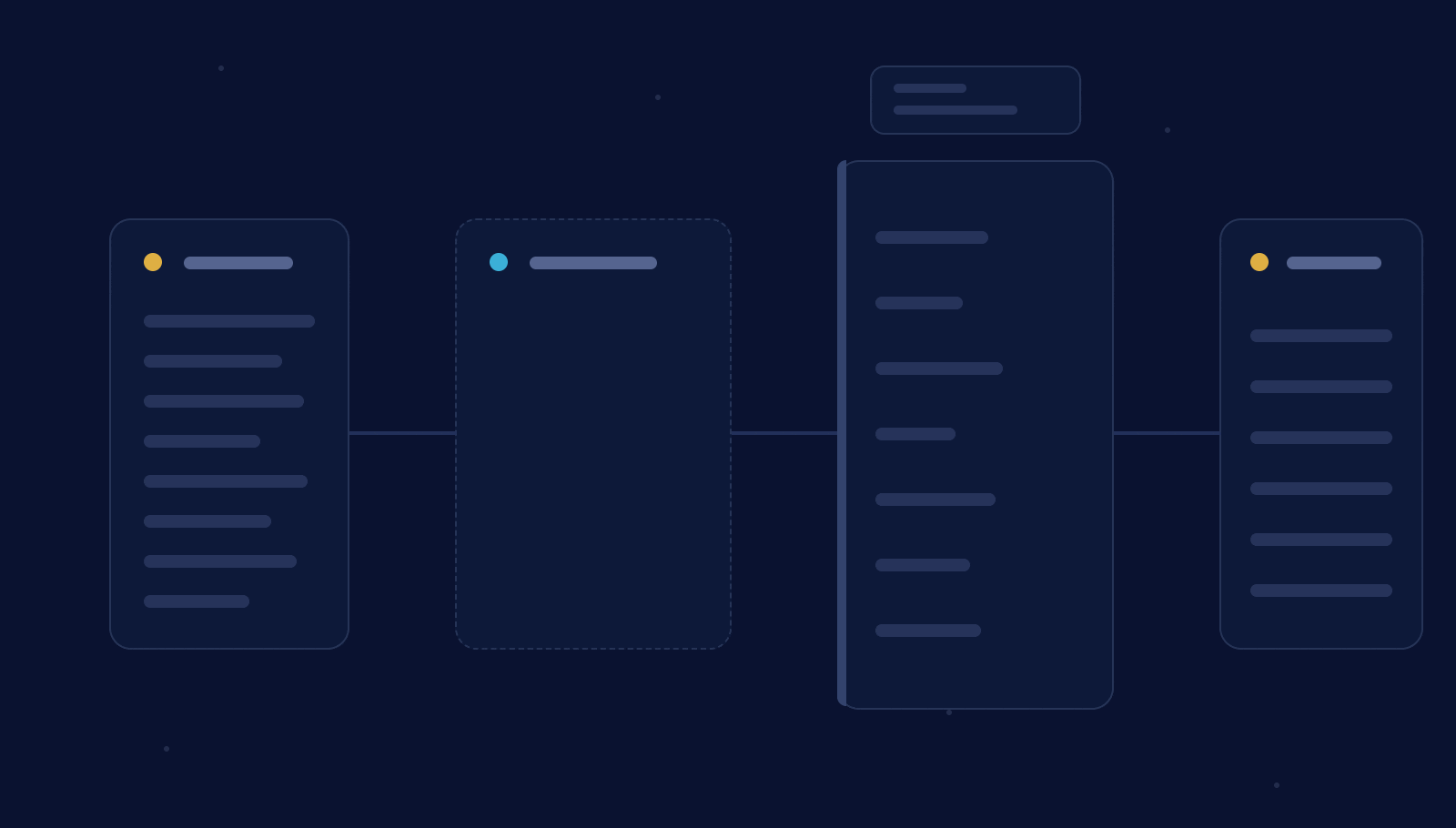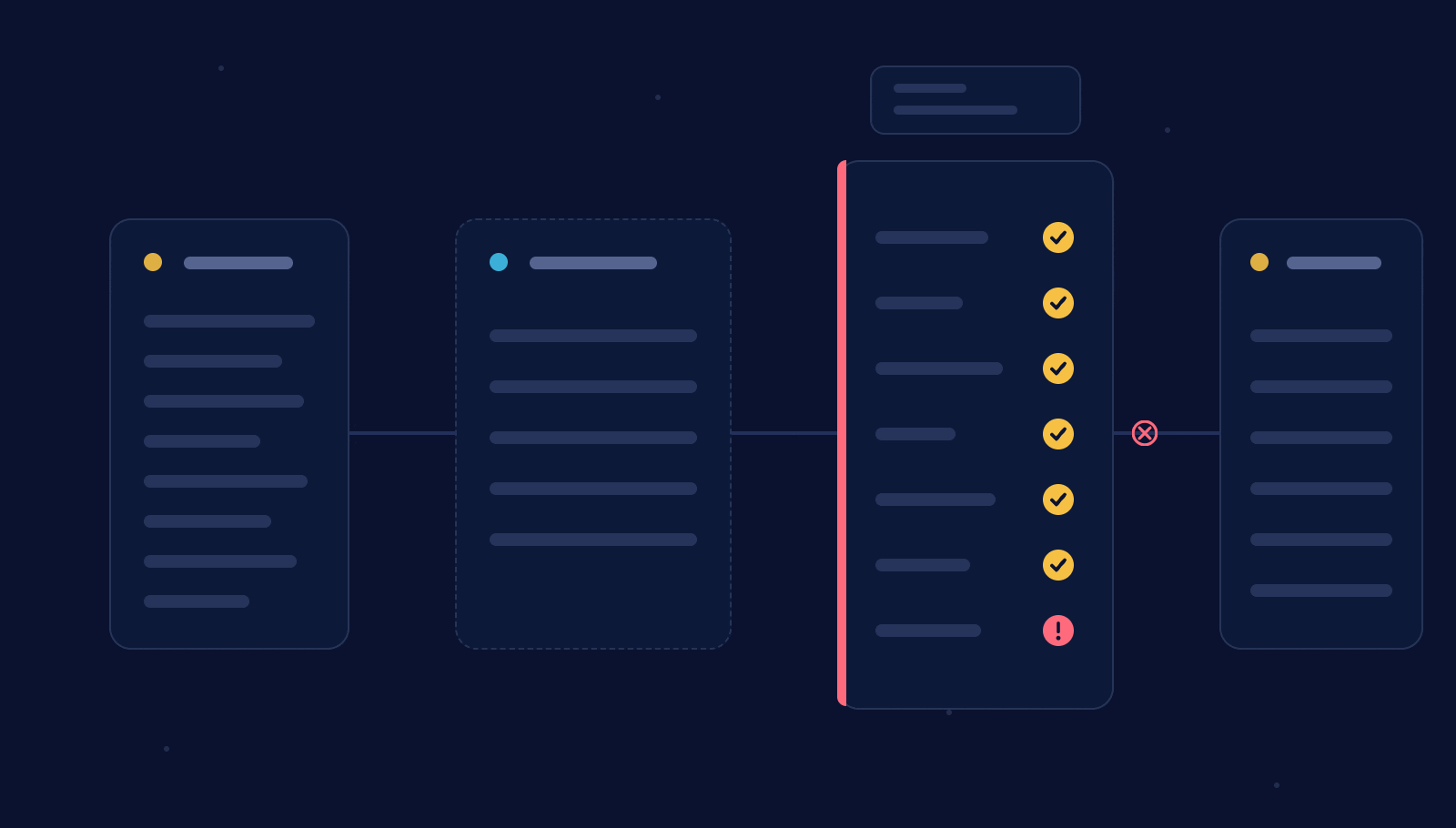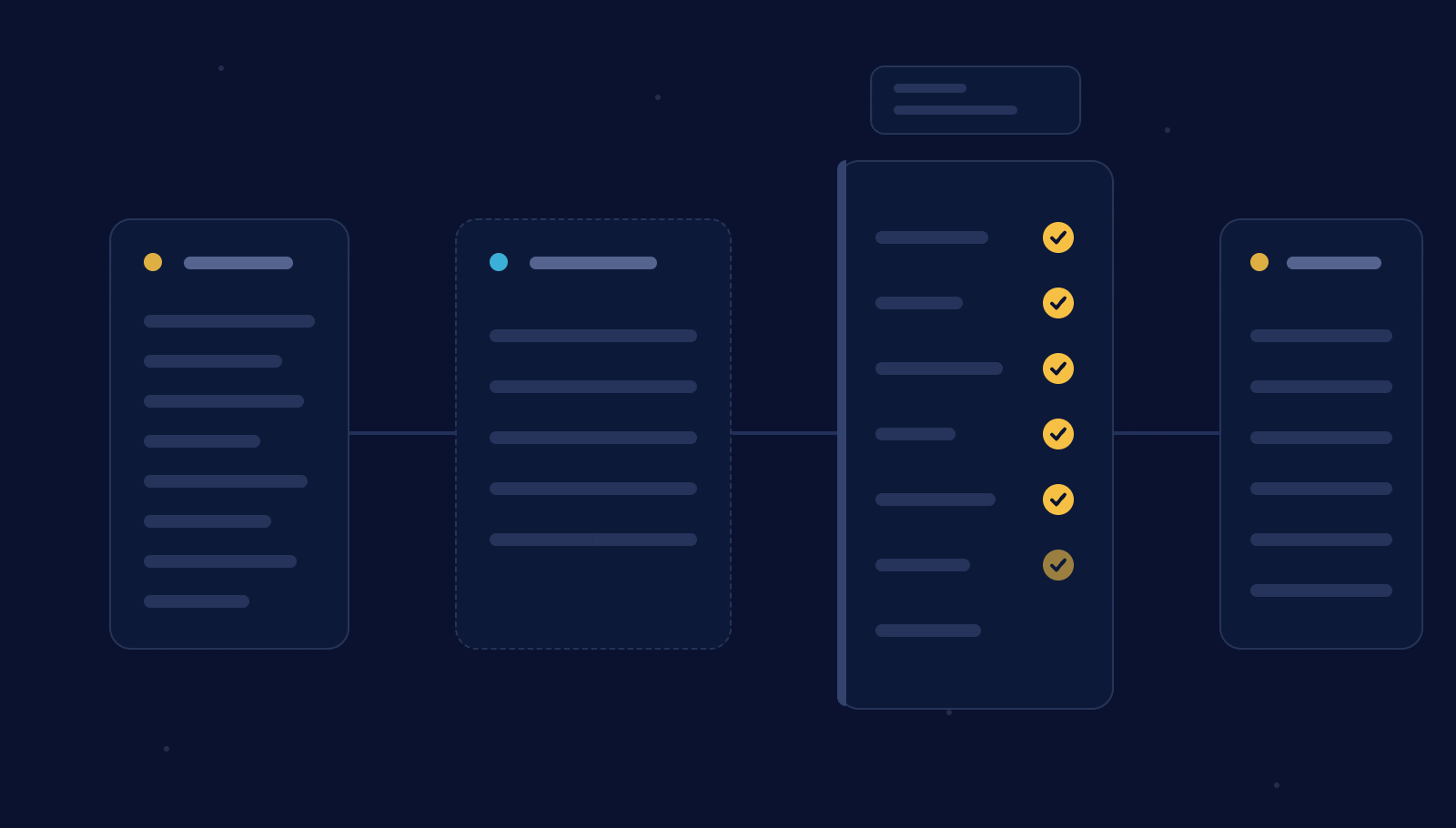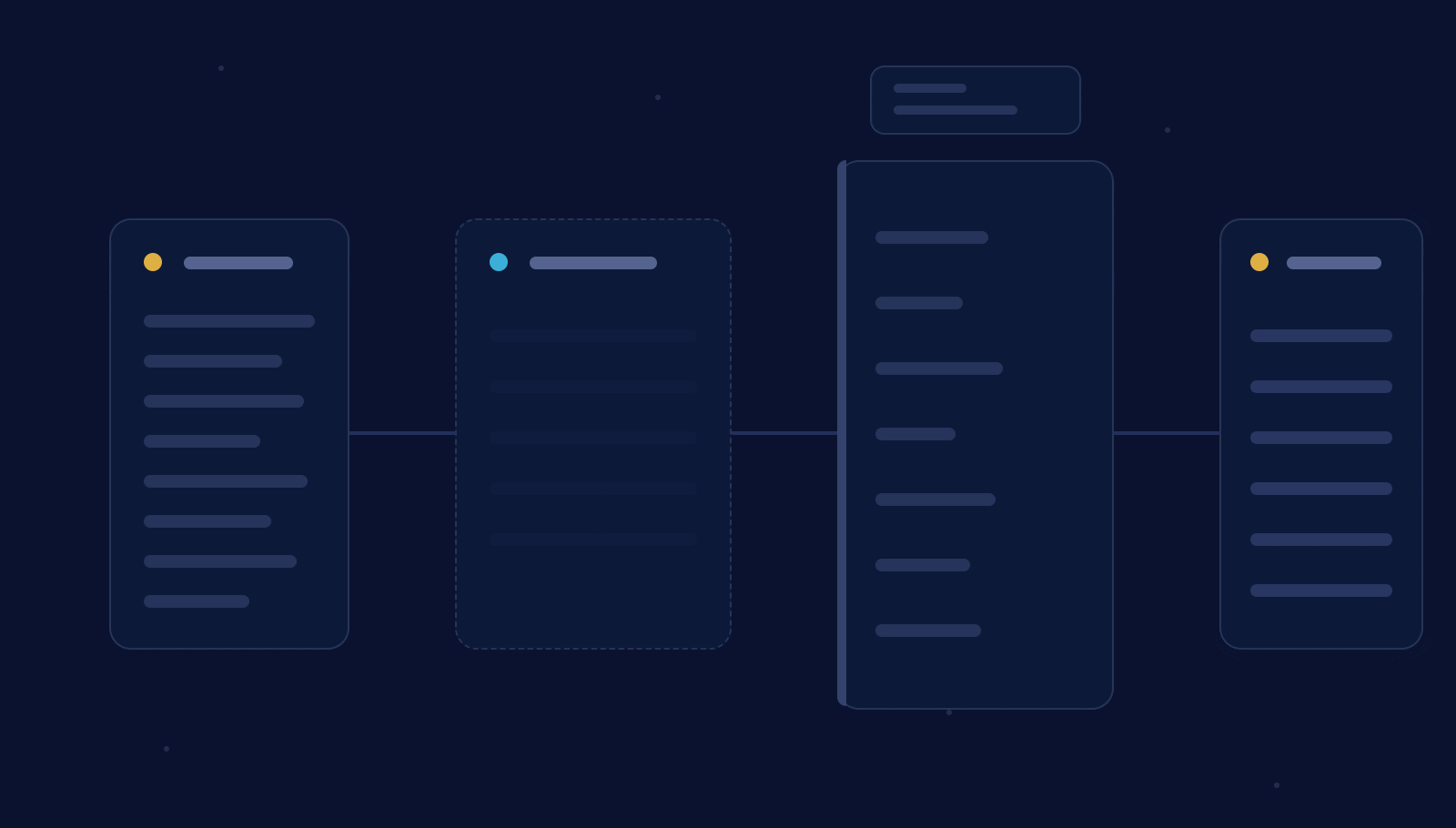
The first test was on Netflix’s Top 10 dataset. The initial run stopped at the gate. Our contract said every film should have “N/A” as the season title, but the agent found nine rows that didn’t match. The contract was wrong, not the data. We fixed it, started a fresh run, and the second attempt published cleanly, with the total reconciling to exactly 185,656,120,000 hours viewed.
We ran it again on an NFL play-by-play pipeline (converting play description strings into structured stat tables). It caught a parser bug that left 1,723 completed passes without matching receptions, exactly the kind of thing a "successful" run hides.
Below, we dig a bit more into how the skill works. Give it a read, or point your coding agent at this URL and try it yourself.