We build AI systems for a living. In production today, that means LangGraph wired into Belvedere: governed pipelines, human approvals, audit trails, provenance, etc.
But for this project, I wanted to kick the tires on something new: Flue, the agent framework from the Astro team. I’ve long been a fan of Astro for web development, so when they released Flue, I wanted to take it for a spin.
Initially I went down the path of adding Flue to background tasks (bug ticket sync, feedback triage, opportunity discovery, etc), but then decided to build something a little more fun, an 'agentic analyst org' powered by Flue.
It's completely free to use if you want to head to https://www.belvederelabs.ai/ and try it out with your data.
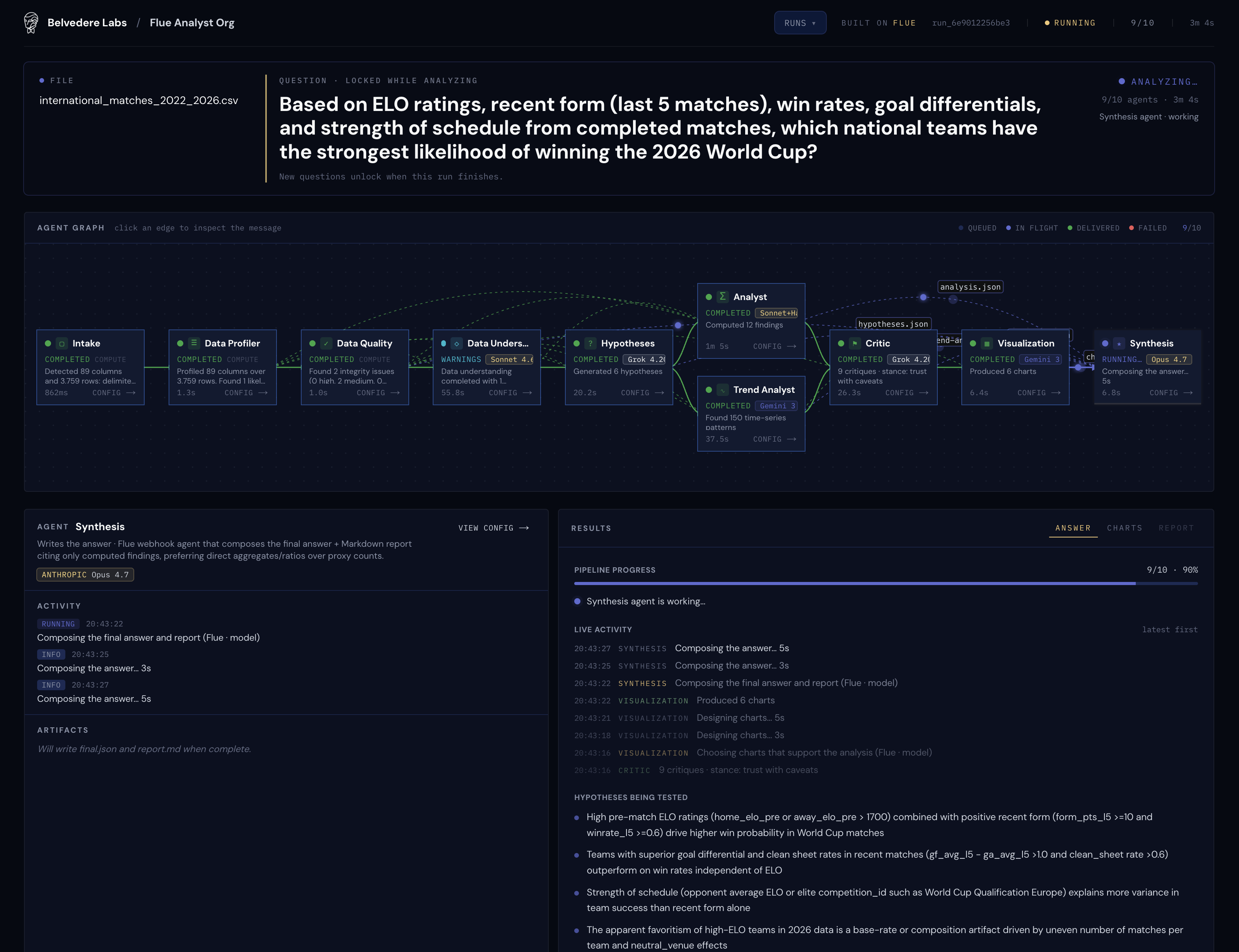
Flue Analyst Org | Belvedere Labs: drop a CSV and get an analyst's answer in a couple of minutes.
The data: 3,759 international matches assembled by Belvedere
We did not hand-roll the dataset. We built it in Belvedere, the same governed pipeline system we use in production.
The pipeline ("World Cup International Match Dataset") is eight nodes and seven edges in the canvas that was assembled by connecting our source API and using the following prompt:
"Pull senior men's international football fixtures and per-match statistics from the API-Football REST API, then computes leak-free pre-match features with all available statistics"
It flows like this: API-Football Fixtures → Filter & Dedupe → API-Football Match Statistics → Filter Senior Men's National Teams → Compute Pre-Match Features → Join Stats & Result Metrics → Output CSV .
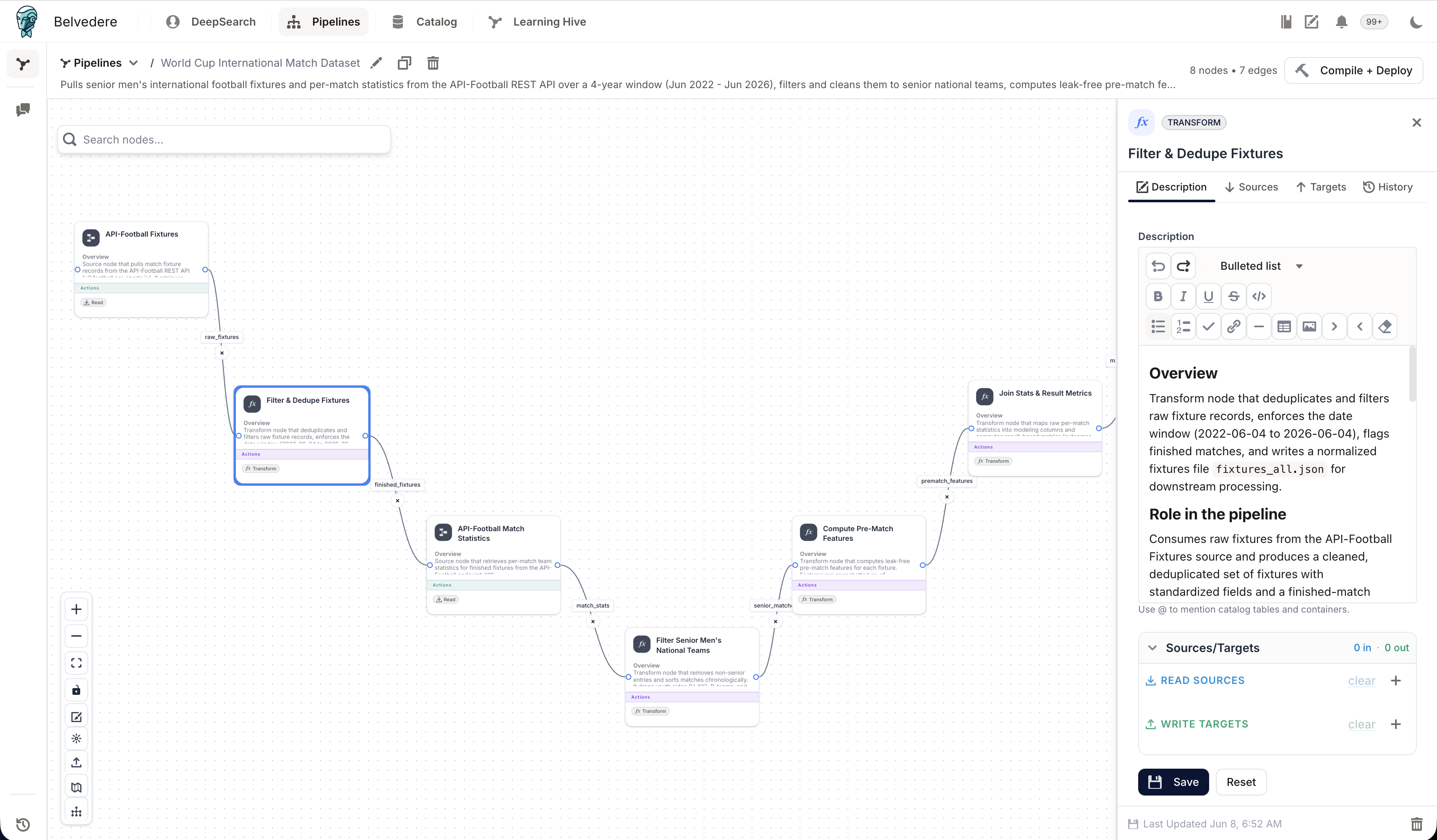
The Belvedere pipeline that builds the dataset: API-Football sources, dedupe and date-window, the senior-team filter, leak-free pre-match features, and the result-metric join.
We included every pre-match feature available, including ELO, form, rest days, head-to-head, etc.
The result: one clean CSV international_matches_2022_2026.csv, 3,759 rows and 89 columns, more than half of which are friendlies. Belvedere's job ends there. We export and hand it to the Flue Analyst Org.
Then we asked the hard question that every football fan litigates in a group chat: based on all this, who wins the world cup in 2026? Use ELO, recent form, strength of schedule, and whatever else you can compute.
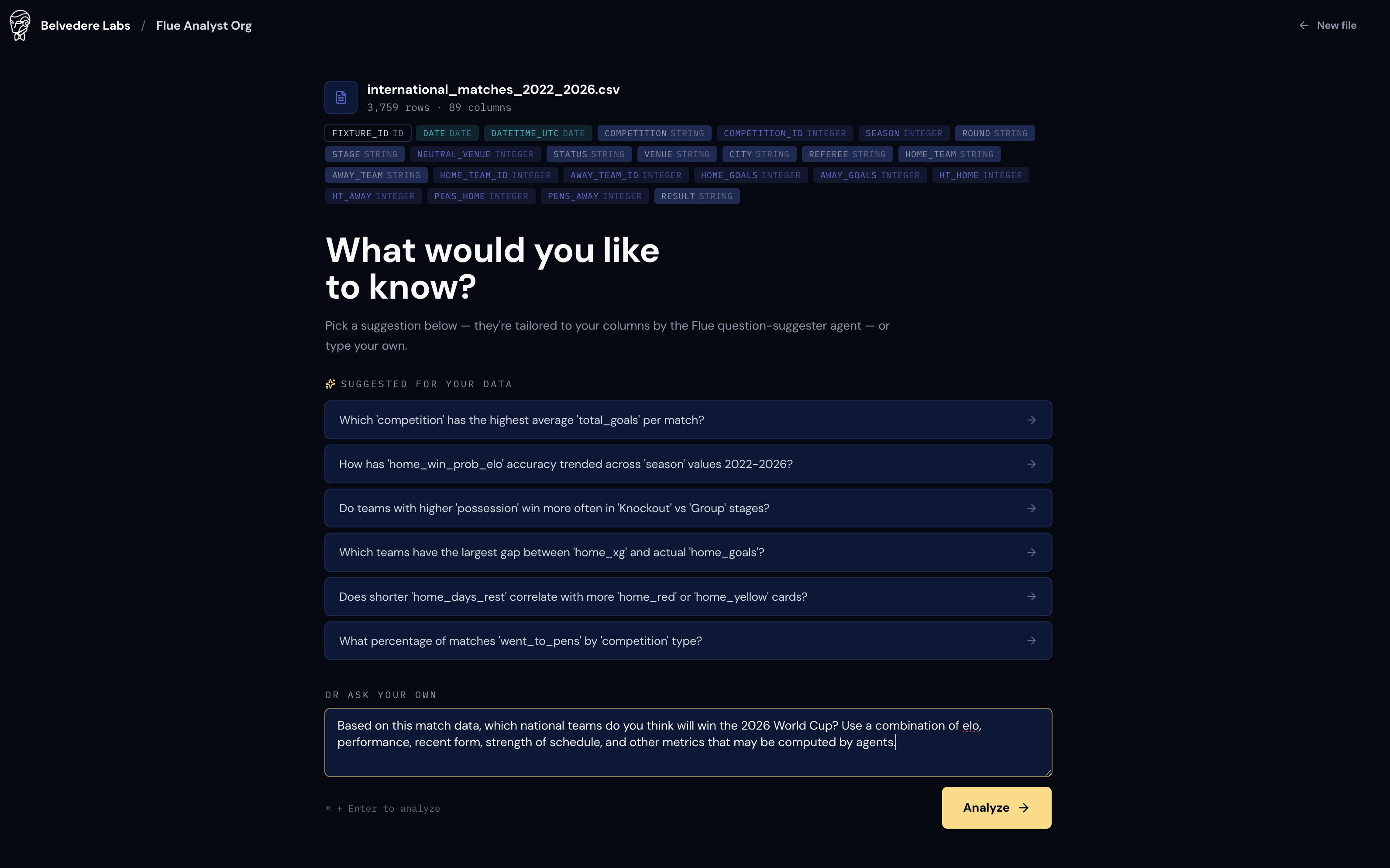
Uploading the 3,759-row, 89-column CSV and asking who wins in 2026.
Ten agents in a line (three of them are not AI)
Flue spins the work across ten agents:
Intake → Profile → Quality → Data Understanding → Hypotheses
→ (Analyst ‖ Trend) → Critic → Visualization → Synthesis
The first three, Intake, Profiler, and Quality, are plain deterministic Node. No model involved, on purpose. Counting rows, inferring types, finding the duplicate, flagging the 49-day gap in the dates: we shouldn't pay LLM latency or invite LLM creativity. They live in the orchestrator and run in milliseconds.
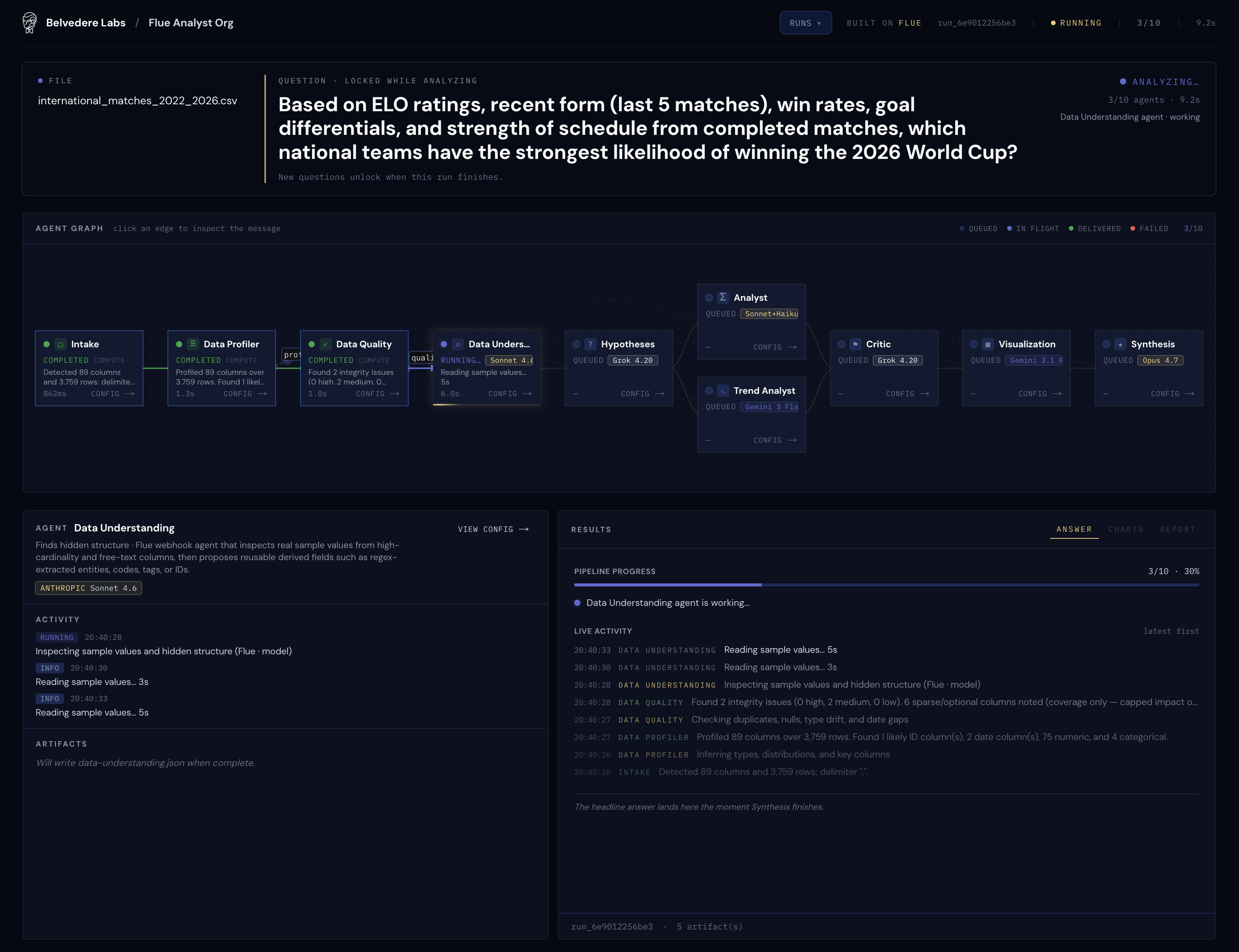
The ten-agent assembly line mid-run, three agents deep, with each node showing its model chip.
The cleverest agent is the Analyst, which is a hybrid. A model writes a plan, such as group, aggregate, time-series, or segment-compare. Then Node executes that plan against the actual rows, and then a second, cheaper model reads the computed numbers back into plain English. The model decides what to compute.
Everything the deterministic side calculates gets dropped into what we call a "locked ledger," and the writer agents are told to cite only numbers that appear in it.
Giving each agent a different model
The genuinely fun part of doing this on Flue is that each agent runs whatever frontier model is best at its specific job, routed through OpenRouter.
Here's the lineup:
Agent | Model | Lab | What it's actually doing |
|---|---|---|---|
Data Understanding | Sonnet 4.6 | Anthropic | Reads the weird free-text columns and proposes derived fields. |
Hypotheses | Grok 4.20 | xAI | Turns "who wins the World Cup" into guesses. |
Analyst (plan) | Sonnet 4.6 | Anthropic | Disciplined. Won't invent an operation or a column that isn't in the schema. |
Analyst (interpret) | Haiku 4.5 | Anthropic | Fast and cheap. Reads computed numbers into one-sentence evidence. |
Trend Analyst | Gemini 3 Flash | Labels the shape of the pre-computed time series. | |
Critic | Grok 4.20 | xAI | The designated contrarian. Red-teams every finding. |
Visualization | Gemini 3.1 Flash Lite | Picks chart types against a fixed schema. | |
Synthesis | Opus 4.7 | Anthropic | The best writer in the lineup. Composes the final answer and report from the locked ledger. |
The reasoning behind the casting is mundane and that's the point: Grok gets the two jobs that reward a contrarian (dreaming up hypotheses and tearing them down), Gemini Flash gets the fast labeling jobs, Sonnet gets the disciplined "don't make things up" jobs, and Opus, the strongest writer, only shows up at the very end to write the report.
The verdict: Argentina
About four minutes later, the pipeline landed on its answer: Argentina (of course I'll be cheering for Team USA until the final seconds).
Mean ELO of 1,709, a 79.2% win rate across 48 matches, with Spain, Morocco, and Portugal as the next tier. Morocco fields the meanest defense in the set, conceding 0.42 goals per game over its last five, with Argentina right behind at 0.45. Japan, of all teams that qualified, tops the recent scoring charts at 2.6 goals a game.
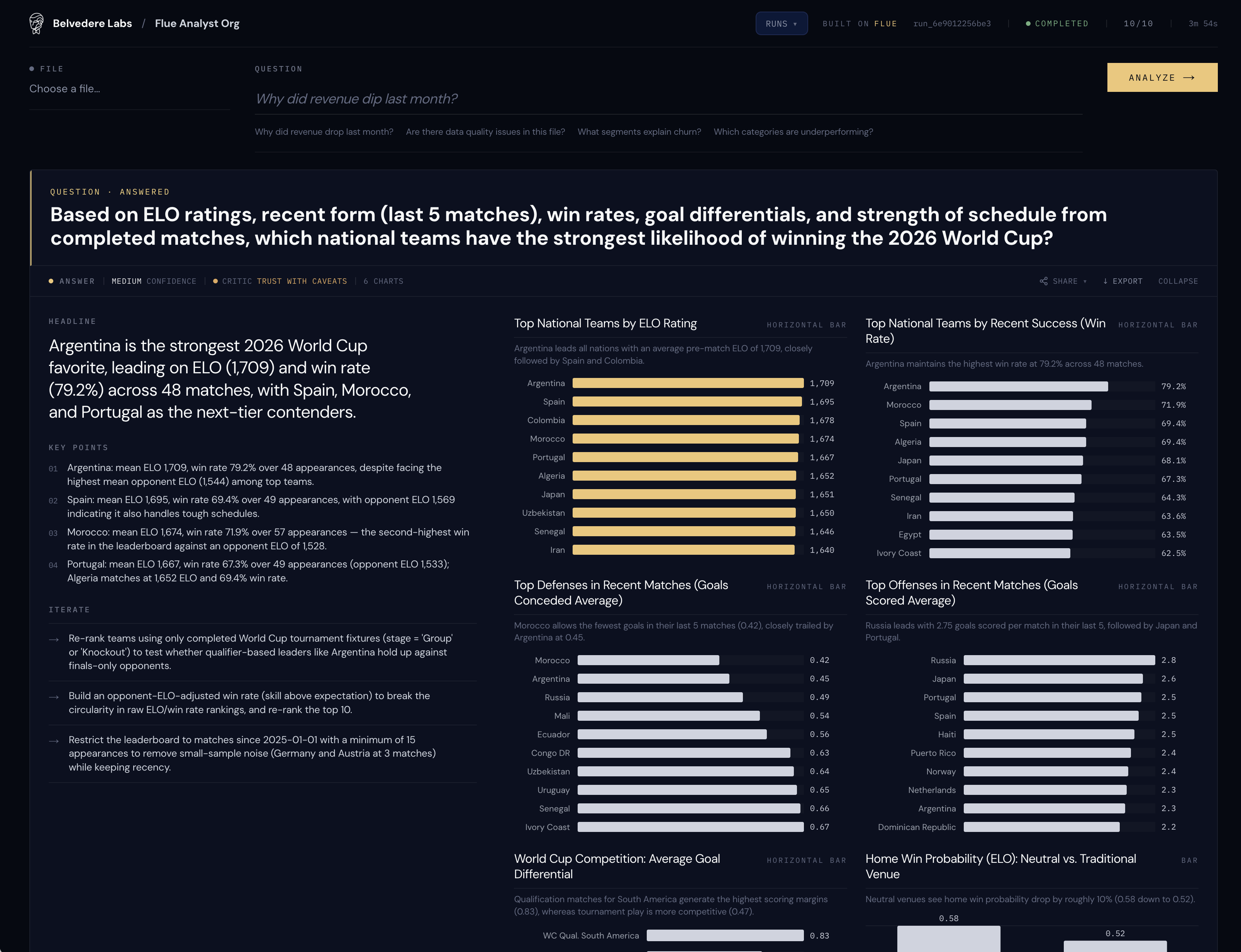
The completed answer: Argentina, with the ELO, win-rate, defense and offense charts.
Confidence: medium. The Critic's official verdict: trust with caveats. Which is exactly the right verdict, and brings us to the actual reason we're writing this.
The best feature is the one that tells you it might be wrong
The Critic: it read the same shiny leaderboard everyone else produced and immediately started poking holes:
A lot of these "contenders" have fewer than 25 matches in the recent window, so some of those win rates are based off of three games.
The dataset has 49-day gaps, which means "last five matches" describes wildly different stretches of time for different teams.
xG is missing for 43-94% of rows, so you can't cross-check whether the goals a team scored were goals it actually deserved.
And the average goal differential in qualifiers is ~2.9x higher than in tournament play, a polite, data-driven way of saying that some teams really beat up on those who didn't qualify.
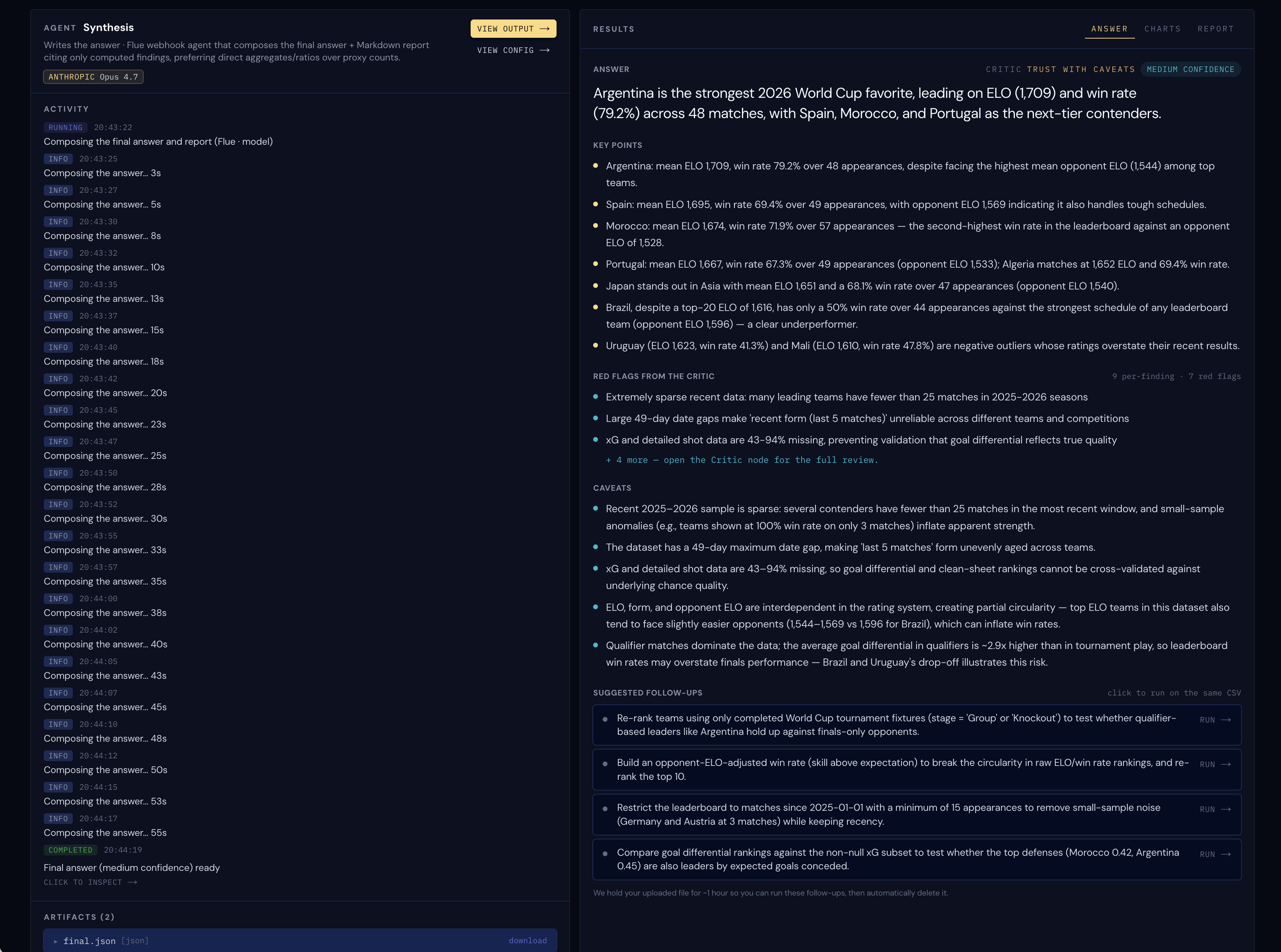
The Synthesis agent (Opus 4.7) writing up the Critic's red flags and caveats.
And then it hands you the fix
Here's the part that turned a neat demo into something we actually respected: the Critic doesn't just complain. Every caveat comes back as a one-click follow-up that re-runs on the same file. "Win rates are inflated by friendlies" isn't a dead end. It is a button.
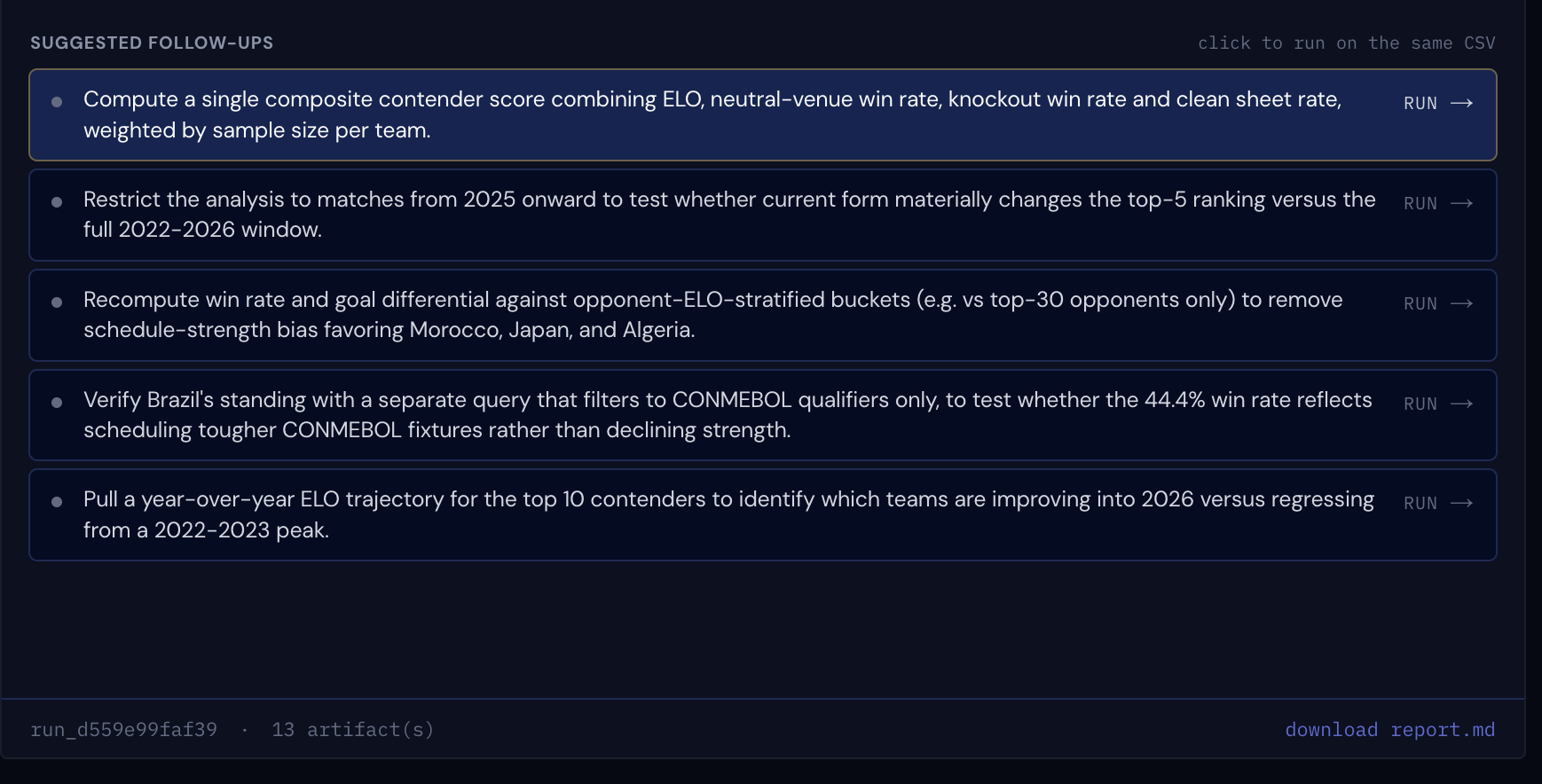
Every caveat comes back as a one-click follow-up that re-runs on the same CSV.
So we took its advice and re-ran the whole thing on competitive matches only, with no friendlies. The numbers moved in exactly the direction the Critic had warned they would. Argentina's win rate dropped from that gaudy 79.2% to a much more believable 67.7% over 31 competitive appearances; its ELO actually ticked up to 1,723 (it's been playing, and beating, better teams); and the headline widened to "Argentina, Spain and Morocco." Strip out the friendlies and Morocco stops looking like a regional bully and starts looking like a real contender, with the best win rate of the top group at 75% and the meanest defense in the field at a 0.67 clean-sheet rate. Türkiye, meanwhile, posts an 83.3% knockout win rate on a sample small enough that the chart politely tells you so.
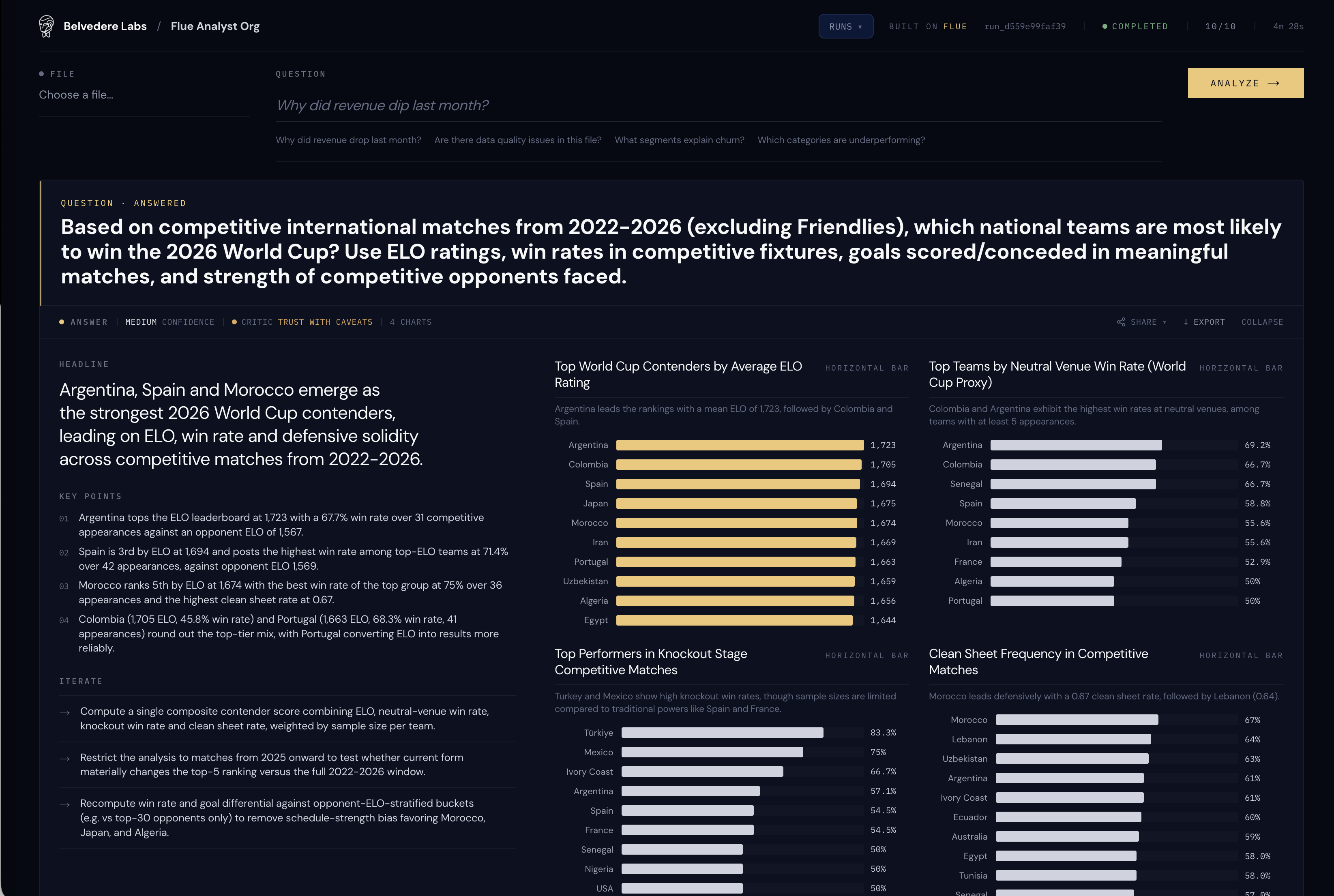
The competitive-only re-run, excluding friendlies. Now Argentina, Spain and Morocco.
Same data, one honest constraint, a visibly better answer. That loop of answer, critique, re-run, and sharper answer aligns with the latest trends in agentic coding too.
Then we pushed the loop again. Build an opponent-ELO-adjusted win rate to break the circularity in the rankings.
The pipeline ran. And then it slapped its own answer with a big red CRITIC: DO NOT TRUST, a LOW CONFIDENCE badge, and a headline that opens, more or less: "a true opponent-ELO-adjusted ranking was not actually computed." In other words: I tried and produced a leaderboard, but it is just raw win rate with opponent ELO printed next to it. It is not the thing you asked for, so do not quote me.
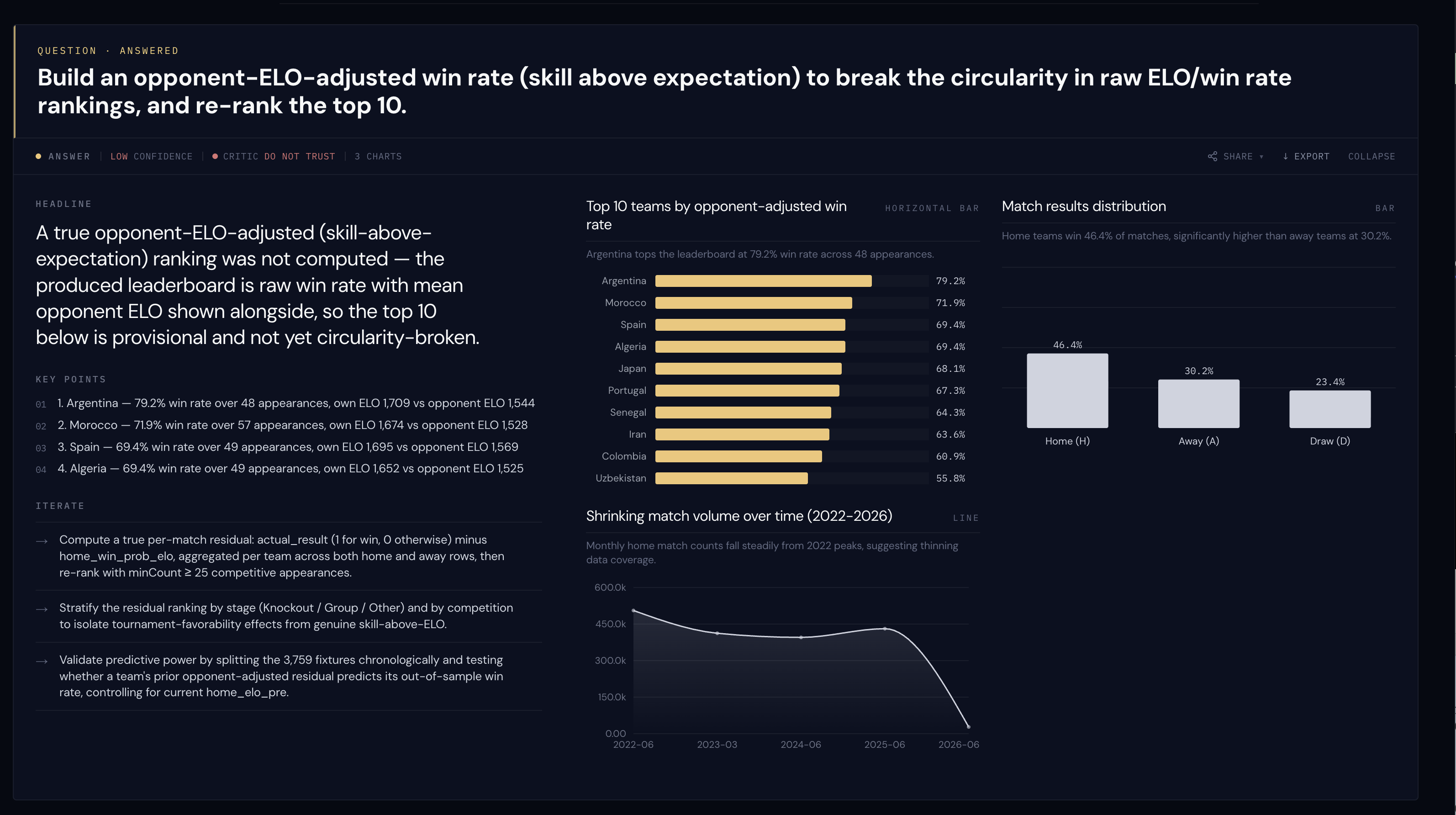
The opponent-ELO-adjusted run flags its own answer: low confidence, "Critic: do not trust."
That's the moment Flue, and the way we wired it together, helped include the human. A demo that confidently hands you a wrong number is a liability. A demo that says "I attempted this, I did not actually do the thing you asked, here is precisely why, and you should not believe this leaderboard" is the kind of AI system we are interested in shipping.
So, did I like Flue?
A resounding yes. It was easy to use, worked well, and deployed with ease (things I'd expect from the team behind Astro). A few highlights of why Flue worked for this project:
HTTP agents fit the shape of the app. Each pipeline step is an addressable Flue endpoint, so the Next.js app can call
POST /agents/<name>/<runId>and pass typed artifacts forward.The product stays in control. Next.js owns uploads, run state, UI progress, artifacts, charts, and follow-up questions. Flue handles the agent harness.
Not every step needs a model. Intake, profiling, quality checks, and analysis execution run as deterministic Flue agents with no LLM call.
Typed outputs keep the pipeline clean. Agents return structured artifacts instead of loose prose, which makes the dashboard possible.
Model routing is per agent. We could use different models for planning, critique, visualization, interpretation, and final synthesis.
The system is inspectable. Each agent has inputs, outputs, timing, status, and artifacts the UI can show.
Flue kept the prototype lightweight. It gave us enough structure for ten agents without turning the weekend project into infrastructure work.
With a test project under my belt, we turned it towards some of our internal processes to see if there was any opportunity for automation.
So we put it to work internally
The sample app worked well enough that we gave Flue a real, unglamorous job. We now use it internally for dev-ticket triage and sync: reading new tickets, sorting and routing them, and keeping our boards from drifting out of sync. Same shape as the World Cup pipeline (small, typed agents behind webhooks), considerably more useful on a Tuesday afternoon.
Go try the Flue Agent Swarm
We parked all of this at belvederelabs.ai, a new playground domain we spun up to test and share Belvedere-adjacent things for Clear Fracture. Drop in a CSV (or pick one of the bundled samples), ask it something, and watch the ten agents argue their way to an answer, complete with the Critic telling you which parts to ignore.
Two honest disclaimers:
It's a toy. A for-fun test app, not a product, not a betting service, and not a substitute for actually doing analysis. Rough edges and half-finished ideas are part of the package.
It deletes your file. Uploads are held for about an hour so you can run follow-up questions, then automatically removed.
A look at the critic agent
A Flue agent is just a TypeScript file with a trigger, a model, a session, and a typed result. This is a trimmed version of the Critic agent: it receives the computed findings, red-teams them, and returns structured caveats the UI can render directly.
// .flue/agents/critic.ts
import type { FlueContext } from "@flue/sdk/client";
import * as v from "valibot";
import { resolveModel } from "../../src/lib/agent-models";
import { promptWithResult } from "../lib/shared";
export const triggers = { webhook: true };
const Critique = v.object({
findingTitle: v.string(),
source: v.picklist(["analyst", "trend"]),
alternativeExplanations: v.array(v.string()),
weaknesses: v.array(v.string()),
whatWouldConvince: v.nullish(v.string()),
});
const Result = v.object({
critiques: v.array(Critique),
redFlags: v.array(v.string()),
overallTake: v.picklist([
"trust",
"trust-with-caveats",
"do-not-trust",
]),
summary: v.string(),
});
export default async function ({ init, payload }: FlueContext) {
const agent = await init({
model: resolveModel("critic"),
});
const session = await agent.session();
return promptWithResult(
session,
`You are a skeptical red-team analyst.
Question:
${payload.question}
Data quality:
${payload.qualitySummary}
Analyst findings:
${JSON.stringify(payload.analystFindings, null, 2)}
Trend findings:
${JSON.stringify(payload.trendFindings, null, 2)}
Critique the findings. Flag weak evidence, alternative explanations,
and whether the answer should be trusted.`,
Result,
);
}
Built on Flue (withastro/flue) by Fred K. Schott. Stack: Next.js 16 orchestrator, Flue webhook agents with valibot schemas, frontier models from Anthropic, xAI, OpenAI, and Google routed through OpenRouter. Dataset built in Belvedere from api-football data. Play with it at belvederelabs.ai.